
Database vs Data Warehouse vs Data Lake
Learn the differences between databases, data warehouses, and data lakes, with real-world examples, use cases, and a practical guide to choosing the right system.




Introduction
In data-driven world, every application, website, and business decision depends on how information is stored and managed. Whether you are running an e-commerce platform, building a SaaS product, or analyzing customer behavior, your data infrastructure plays a critical role in performance, reliability, and growth.
However, many teams struggle to choose between databases, data warehouses, and data lakes. Using the wrong system can lead to slow applications, rising costs, unreliable reports, and limited analytical capabilities. At the same time, modern businesses generate more data than ever, making this decision even more important.
Although these systems may seem similar, they are built for very different purposes. Databases focus on day-to-day operations, data warehouses support business intelligence and reporting, and data lakes enable large-scale analytics and machine learning.
In this guide, you will learn how databases, data warehouses, and data lakes actually work, their strengths and limitations, real-world use cases, and how to choose the right solution for your technical and business needs.
Before exploring each system in detail, it is important to understand how databases, data warehouses, and data lakes fit into a complete data strategy. Although all three are used to store data, they serve different purposes and are designed for specific types of workloads, users, and business goals.
A database focuses on handling real-time transactions, a data warehouse supports analytics and reporting, and a data lake stores raw data for large-scale processing and experimentation. When used together, they form the foundation of a modern, scalable data architecture.
What Is a Database?
Databases are mainly used for secure, accurate, and reliable data management. SQL databases are especially useful for tasks like record keeping, transaction processing, and inventory tracking because they maintain strong data integrity and clear relationships between tables.
In business and project management systems, databases help teams automate workflows, store templates, and manage tasks efficiently. This ensures that information is always consistent and easily accessible.
Many popular platforms we use every day depend on databases. Companies like Netflix, Amazon, and Facebook use different database systems such as MySQL, Cassandra, and other technologies to manage massive amounts of user data and content smoothly.
Common Uses of SQL Databases
Here are some practical examples of how SQL databases are used in real life:
E-commerce Platforms
Used for managing orders, tracking inventory, maintaining product catalogs, and storing customer details.Booking and Reservation Systems
Help handle hotel bookings, travel reservations, appointment scheduling, and event ticketing.Financial and Banking Systems
Store transaction records, manage accounts, process payments, and support accounting operations.Content Management Systems (CMS)
Used to store website content, user profiles, comments, and media files.Business Management Software
Supports employee records, payroll systems, and internal reporting tools.
Limitations of SQL Databases
Although SQL databases are powerful, they are not always ideal for advanced analytics and large-scale data analysis.
Most SQL databases focus on current operational data and do not store long-term historical records by default. Running large and complex queries can be slow and may affect live applications. This is why companies often use data warehouses or analytics platforms for heavy reporting tasks.
Examples of Popular Databases
Some widely used database systems include:
MySQL – Popular open-source database, commonly used for web applications
PostgreSQL – Advanced database with strong performance and reliability
Oracle Database – Enterprise-level database for large organizations
Microsoft SQL Server – Widely used in corporate environments
IBM DB2 – Used in large-scale business systems
Each of these databases is designed to handle different business and technical requirements.
What Is a Data Warehouse?
A data warehouse is a system designed to collect, clean, and store data from multiple sources for analysis and reporting. It helps businesses understand past and present performance by organizing large amounts of structured data in one place.
Unlike regular databases that handle daily transactions, a data warehouse is optimized for analytical workloads (OLAP). It processes historical data and supports complex queries. With the help of a data warehouse, companies and data teams can track trends, measure growth, and make data-driven decisions. Many enterprises use platforms like Snowflake, BigQuery, and Redshift for this purpose.
What Is a Data Warehouse Used For?
A data warehouse is used to analyze business data and generate insights, meaning you can study patterns, compare performance, and improve strategies using accurate information.
It helps organizations:
Monitor sales and revenue
Analyze customer behavior
Track marketing performance
Create dashboards and reports
Support long-term planning
In simple words, a data warehouse turns stored data into business intelligence.
Real-Life Example: Retail Analytics System
A retail company collects data from its website, mobile app, stores, and marketing tools. This data is sent daily to a data warehouse such as Snowflake.
Managers use dashboards to track:
Monthly revenue
Best-selling products
Customer retention
Regional performance
Without a data warehouse, generating these insights would be slow and unreliable.
What Is a Data Lake?
A data lake is a system designed to store large amounts of raw data in its original format. It can hold structured, semi-structured, and unstructured data such as text files, images, videos, logs, and sensor data.
Unlike databases and data warehouses, a data lake does not require data to be cleaned or organized before storage. It uses a “store first, analyze later” approach. With the help of a data lake, companies and data teams can save massive volumes of information at low cost and use it later for analytics, artificial intelligence, and machine learning projects. Popular data lakes include Amazon S3, Azure Data Lake, and Google Cloud Storage.
Why Are Data Lakes Commonly Used?
Companies use data lakes because they offer affordable, flexible, and scalable storage for large volumes of raw data.
Key benefits include:
Low-Cost Storage – Uses cloud-based systems to reduce data storage expenses.
Supports All Data Types – Stores structured, semi-structured, and unstructured data in one place.
Flexible Usage – Allows teams to use the same data for analytics, reporting, and AI projects.
Strong AI and ML Support – Provides large datasets for training machine learning models.
Easy Scalability – Expands easily as data volumes grow.
Real-Life Example: Technology Data Platform
A technology company collects website activity, mobile app logs, customer chats, system data, and media files. All this raw information is stored in a data lake using Amazon S3.
Data scientists then use this data to build recommendation systems, detect fraud, improve user experience, and train AI models.
Without a data lake, storing and using such large and diverse datasets would be expensive and difficult.
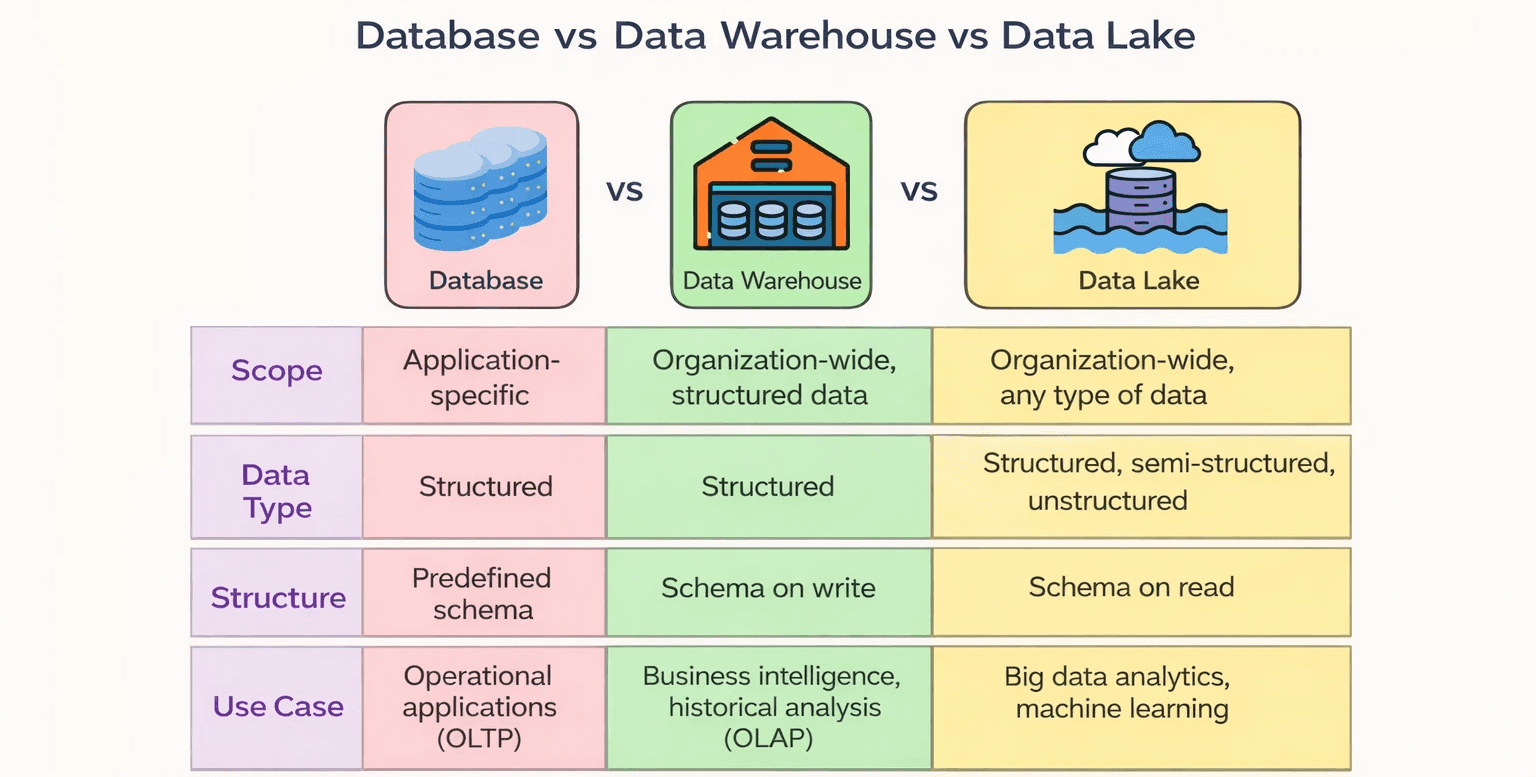
What Are the Key Differences Between a Database, Data Warehouse, and Data Lake?
Although databases, data warehouses, and data lakes are all used to store data, they are designed for very different purposes in a company’s data ecosystem.
A database focuses on running daily business operations. It stores live data that applications need to function, such as user accounts, orders, and payments.
A data warehouse focuses on business intelligence. It collects structured data from multiple systems and organizes it for reporting, dashboards, and long-term analysis.
A data lake focuses on flexibility and scale. It stores raw data in its original form so that companies can use it later for analytics, machine learning, and research.
Most modern organizations use all three together to manage data efficiently.
Database vs Data Lake vs Data Warehouse: Detailed Comparison Table
The following table compares databases, data warehouses, and data lakes across key technical, business, and operational factors.
Feature | Database | Data Lake | Data Warehouse |
|---|---|---|---|
Primary Purpose | A database is mainly used to run applications by storing and managing live operational data such as user accounts, orders, and payments. | A data lake is used to store large volumes of raw data for future analysis, machine learning, and research purposes. | A data warehouse is designed to analyze business data and generate reports, dashboards, and insights. |
Workload Type | It handles transactional workloads like inserting, updating, and deleting records in real time (OLTP). | It supports analytical, big data, and machine learning workloads using batch and streaming processing. | It handles analytical workloads (OLAP) such as aggregations, summaries, and trend analysis. |
Type of Data | It mainly stores structured data and some semi-structured data in organized tables. | It can store structured, semi-structured, and unstructured data such as logs, images, videos, and JSON files. | It stores cleaned, structured, and processed data ready for business analysis. |
Schema Approach | The structure of data is defined before storage, which ensures consistency and accuracy. | Data is stored first without a fixed structure, and schema is applied later when reading the data. | Data must follow a predefined structure before being loaded into the system. |
Data Processing | Data is processed immediately when users interact with applications. | Data is processed in batches or real time using big data tools. | Data is processed through ETL pipelines before analysis. |
Data Freshness | Data is always current and reflects real-time business activity. | Data freshness depends on how often data is ingested from source systems. | Data freshness depends on scheduled data loading processes. |
Typical Users | Mainly used by software developers and application engineers. | Mostly used by data engineers, data scientists, and AI teams. | Mainly used by business analysts, managers, and decision-makers. |
Query Performance | Provides very fast responses for small and frequent queries. | Performance depends on data volume and processing tools. | Optimized for running complex and heavy analytical queries. |
Storage Cost | Storage costs are moderate because data is structured and managed carefully. | Storage is relatively cheap because raw data is stored in cloud-based systems. | Storage and processing costs are higher due to data transformation and optimization. |
Scalability | Can scale, but scaling requires careful planning and infrastructure upgrades. | Highly scalable and can handle massive amounts of data easily. | Scales well, but often at a higher cost. |
Data Governance | Has strong built-in rules for data validation, access control, and consistency. | Requires additional tools and policies to manage data quality and security. | Includes strong governance to ensure accuracy and compliance. |
Security | Offers high security with authentication, authorization, and encryption features. | Security must be configured properly to avoid data exposure. | Provides enterprise-level security and compliance support. |
Analytics Capability | Limited analytical support and not suitable for heavy reporting. | Supports analytics after data is processed and organized. | Excellent support for reporting, dashboards, and business intelligence. |
Machine Learning Support | Not designed for training machine learning models. | Highly suitable for AI and machine learning projects. | Can support ML analytics but not raw training data. |
Historical Data | Usually keeps limited historical data for operational needs. | Stores large amounts of historical data for long-term analysis. | Maintains long-term historical data for business reporting. |
Data Cleaning | Minimal cleaning is done to support transactions. | Data is cleaned and prepared later when needed. | Data is cleaned before being stored for analysis. |
Flexibility | Less flexible because of predefined structures. | Very flexible and adaptable to new data types. | Less flexible due to fixed schemas. |
Maintenance | Easier to maintain compared to large analytics systems. | Requires regular monitoring to avoid data disorder. | Requires significant effort to maintain and optimize. |
Best Use Case | Best for managing online transactions, user authentication, and daily operations. | Best for storing logs, sensor data, and machine learning datasets. | Best for analyzing sales, customer behavior, and performance metrics. |
Real-World Example | Used in e-commerce checkout and banking systems. | Used in streaming platforms for storing activity logs. | Used by enterprises for executive dashboards. |
Common Tools | Examples include MySQL and PostgreSQL. | Examples include Amazon S3 and Azure Data Lake. | Examples include Snowflake and Google BigQuery. |
Database vs Data Warehouse vs Data Lake: How to Choose the Right Solution
Choosing between a database, data warehouse, and data lake depends on how you use your data. There is no single solution that fits every business. The right choice depends on your workload, data size, and business goals.
If you mainly run applications and handle real-time transactions, a database is the best option. It is built for speed and accuracy but is not suitable for heavy analytics.
If your focus is reporting, dashboards, and business insights, a data warehouse is more suitable. It organizes data from multiple sources and allows fast analytical queries without affecting live systems.
If you collect large volumes of raw and unstructured data, a data lake is the right choice. It offers low-cost storage and supports big data and machine learning use cases.
In practice, many companies use all three systems together to create a balanced and scalable data environment.
FAQs
1. Which One Is AWS Data Warehouse and Data Lake?
On AWS, Amazon Redshift is the primary data warehouse service used for analytics, reporting, and business intelligence. It stores structured and processed data for fast querying. Amazon S3 acts as the main data lake, where companies store raw files, logs, and large datasets. In most architectures, data is first stored in S3 and then analyzed in Redshift, creating a complete cloud analytics ecosystem.
2. What’s the Difference Between a Data Lake and a Data Warehouse?
A data lake stores raw data in its original format and is mainly used for big data processing, experimentation, and machine learning. A data warehouse stores cleaned and structured data optimized for reporting and dashboards. In practice, data lakes offer flexibility and low cost, while data warehouses provide accuracy, performance, and business-ready insights.
3. What’s the Difference Between a Database, a Data Warehouse, and a Data Lake?
A database supports daily operations such as user logins, orders, and payments. A data warehouse is designed for analyzing historical business data and generating reports. A data lake stores large volumes of raw data for advanced analytics and AI. Together, these systems form a complete data pipeline from operations to insights.
4. Is a Data Warehouse Bigger Than a Database?
In most organizations, a data warehouse is larger than a database because it stores historical data collected from multiple systems over many years. A database mainly contains current operational records. Since warehouses are built for long-term analysis and reporting, their data volume usually grows much faster than that of transactional databases.
Conclusion
Choosing the right data system is essential for building reliable, scalable, and data-driven applications. Databases support daily operations and real-time transactions, data warehouses enable business intelligence and reporting, and data lakes provide flexible storage for large-scale analytics and machine learning. Each system serves a unique purpose, and using the wrong one can lead to performance issues and inaccurate insights. By understanding their differences, strengths, and use cases, organizations can design a balanced data architecture that supports growth, improves decision-making, and maximizes the long-term value of their data.



