
What Is Database Optimization? Everything You Need to Know About Performance & Scaling
Database optimization improves how data is stored, retrieved, and processed to ensure fast, predictable performance. Learn queries, indexing, and scaling.




As data grows, even well-built systems can start to slow down, queries take longer, dashboards lag, and costs quietly increase. Improving how a database handles these challenges isn’t just a backend task; it directly impacts user experience and scalability. Database optimization is the process of improving database performance by reducing query execution time, optimizing resource usage, and ensuring efficient data retrieval through techniques like indexing, caching, and query tuning. In this guide, we’ll break down practical ways to make your database faster, leaner, and more reliable.
What is Database Optimization?
Database optimization is the process of improving database performance by reducing query execution time, optimizing resource usage, and ensuring efficient data retrieval using techniques like indexing, caching, and query tuning.
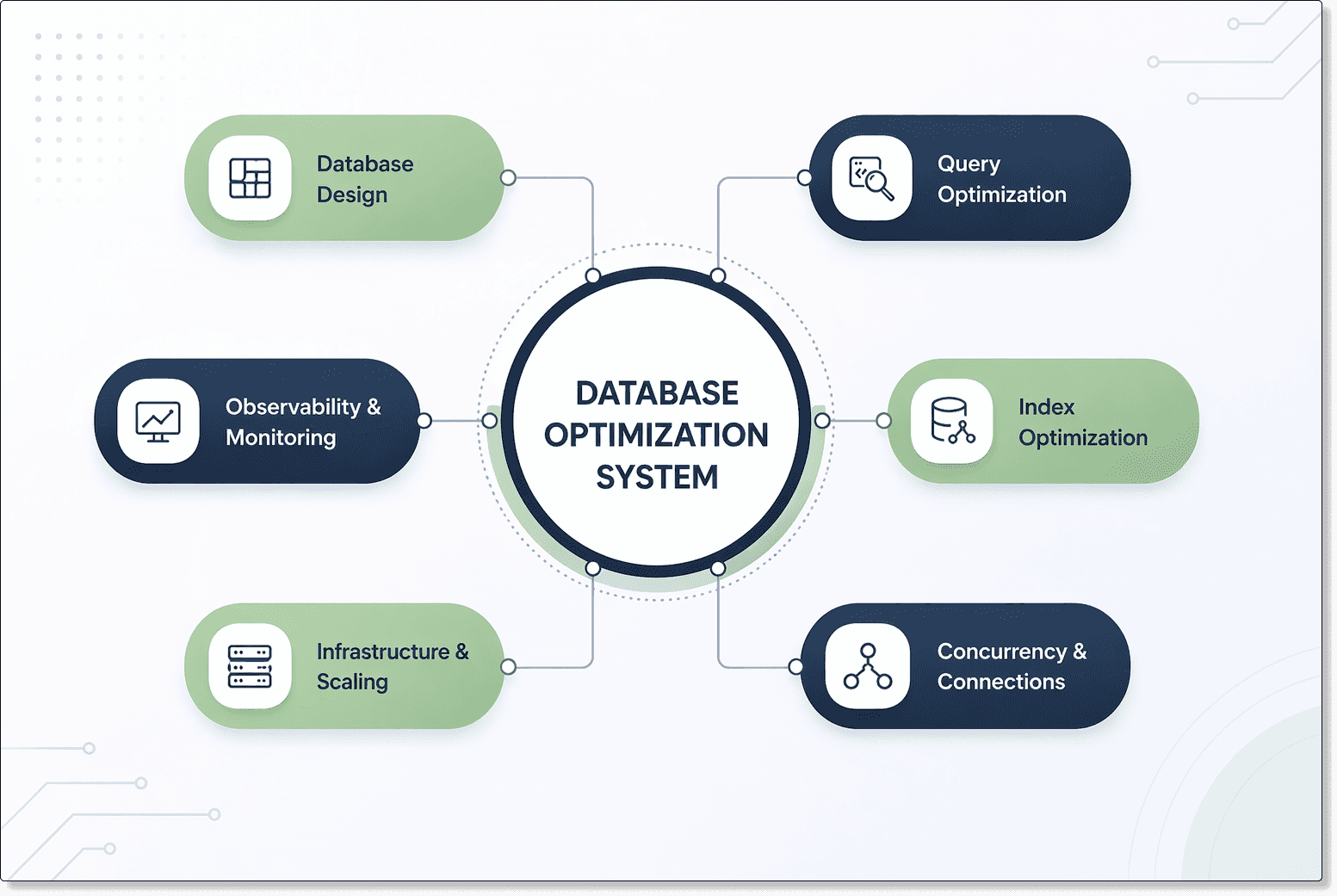
Database optimization is a structured approach to improving the performance, efficiency, storage, and data retrieval of a database system. It involves analyzing SQL queries, refining execution plans, tuning configurations, and applying techniques like indexing, normalization, and caching. It also includes scalability planning, concurrency handling, continuous monitoring, and automated tuning to maintain consistent performance as data and workload demands grow.
Most database performance issues don’t come from infrastructure, they come from queries.
In real-world systems, nearly 85–90% of performance problems trace back to inefficient queries, not hardware limitations. Yet teams often react by scaling servers instead of fixing the root cause, which only increases cost without solving the problem.
The 5 Layers of Database Optimization
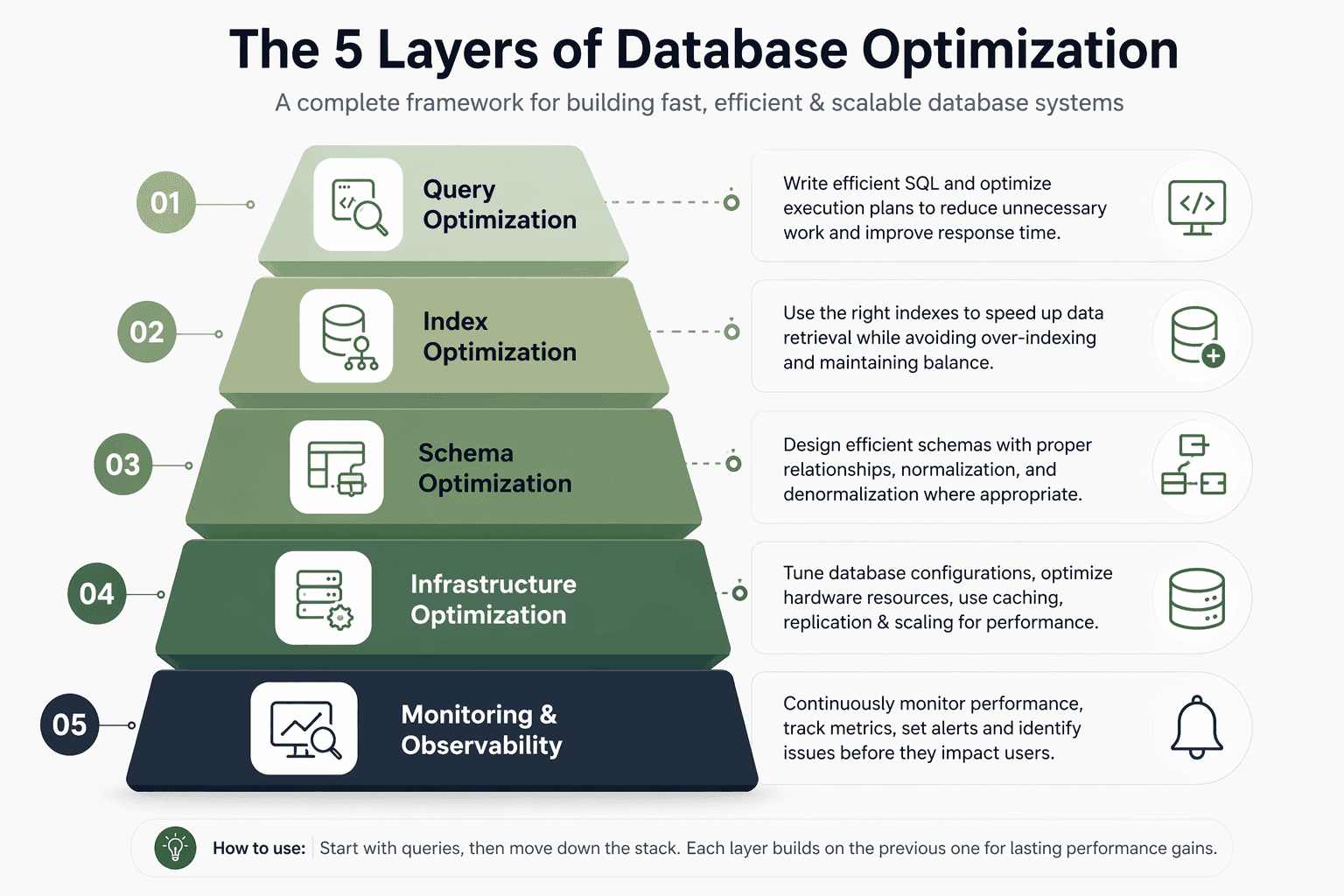
Most teams treat optimization like a checklist add indexes, scale servers, tweak queries, but that approach only works for a while. Real performance comes from understanding that slowdowns are chain reactions across layers, where fixing the wrong layer can hide the actual problem. This framework helps you understand what to optimize, where to start, and why it matters.
Database Design (Where Performance Is Decided Early)
Why it matters:
Every system depends on how data is structured at this layer. A poorly designed schema can lead to excessive joins, redundant data access, and inefficient queries. As data grows, these inefficiencies increase CPU, memory, and I/O usage, making performance issues harder to fix later.
When the schema doesn’t reflect how data is actually accessed, even well-written queries and optimized indexes struggle to deliver consistent performance under load.
What to focus on:
Designing for real access patterns
Don’t model data purely based on theoretical structure. Understand how the application reads and writes data, and design tables around those patterns to reduce unnecessary joins and data movement.
Balancing normalization and denormalization
Normalization improves data consistency, but over-normalization increases query complexity. Use denormalization where needed to reduce joins and improve read performance, especially in high-traffic systems.
Structuring relationships to minimize overhead
Avoid deeply nested relationships that require multiple joins for common queries. Keep frequently accessed data closer together to reduce query execution time.
Planning for scale and growth
Consider how the dataset will grow over time. Use strategies like partitioning or logical data grouping to ensure the schema remains efficient as data volume increases.
Common mistake:
Teams often design schemas based on correctness or best practices without considering actual usage patterns.
This leads to excessive joins, complex queries, and repeated data access. When performance issues arise, teams try to fix them with indexes or infrastructure upgrades, but the core problem, a mismatched schema, remains.
Real-world insight
In many production systems, schema design becomes the hidden cause of performance bottlenecks.
It’s common to see over-normalized tables requiring multiple joins for simple queries, or related data spread across structures that are always accessed together.
In several cases, redesigning the schema, by simplifying relationships or aligning tables with real access patterns, significantly improved performance without changing queries or infrastructure.
Index Optimization (Controlling How Data is Accessed)
Why it matters:
Think of indexes like a book’s table of contents. Without them, the database scans every page to find what you need. With the right index, it jumps directly to the data. But adding too many indexes is like adding too many bookmarks, it slows down updates and creates confusion about which one to use.
What to focus on:

Index for access patterns, not just columns
Don’t index a column just because it exists or is frequently used. Look at your actual queries, what are you filtering (WHERE), sorting (ORDER BY), or joining on? Index those patterns, not isolated fields.Use composite indexes based on real queries
If your query filters by multiple columns (e.g.,user_idandcreated_at), a combined index works better than separate ones. The order also matters, put the most selective or frequently filtered column first.Remove unused or duplicate indexes regularly
Over time, databases collect indexes that are no longer used. These slow down writes and waste space. Regular cleanup keeps performance balanced and predictable.
Trade-off (keep this in mind):
Indexes make reads faster, but every insert, update, or delete has to update those indexes too. More indexes = slower writes + more storage.
Layer interaction (this is key):
If your query is inefficient, even the best index won’t help much
If your query is clean but indexes are wrong, performance will still suffer
Real-world insight:
A common mistake is adding multiple indexes hoping one will “fix” a slow query. It might work temporarily, but without understanding how the query accesses data, it often leads to bloated databases and inconsistent performance.
Schema Optimization (Designing for Reality, Not Theory)
Why it matters:
Your schema is the foundation of performance. It decides how data is stored, related, and retrieved. A perfectly “clean” (highly normalized) design may look ideal on paper, but in real-world applications it can lead to too many joins and slower queries. Good schema design balances data integrity with practical performance.
What to focus on:
Normalize for integrity, denormalize for performance
Use normalization to avoid duplication and keep data consistent. But when queries become too complex or slow, selectively denormalize (e.g., storing computed or repeated values) to reduce joins and speed up access.Design around query patterns, not just data structure
Don’t design tables only based on how data is stored, design them based on how data will be read. Identify your most frequent queries and structure tables to support them efficiently.Reduce join complexity where possible
Too many joins increase execution time and complexity. Simplify relationships, use fewer tables when practical, and consider pre-aggregated or flattened structures for heavy read workloads.
Common mistake (real-world):
Teams often over-normalize in the name of “best practices,” splitting data into many small tables. This forces queries to join multiple tables for simple requests, making performance worse as data grows.
Layer interaction (why this layer is critical):
Poor schema leads to complex queries
Complex queries reduce index effectiveness
Result: slower performance even with good indexing
Infrastructure Optimization (Scaling What Already Works)
Why it matters:
A common theme you’ll see in real-world discussions (especially on developer forums like Reddit) is this: “We upgraded our database instance and it got faster… for a while.”
Infrastructure helps, but only if the foundation is solid. If queries, indexes, and schema are inefficient, better hardware just delays the problem. Once those are fixed, infrastructure becomes a powerful multiplier.
What to focus on:
Memory, caching, and I/O performance
Many engineers report big wins just by improving cache usage (like increasing buffer/cache size) instead of upgrading CPUs. Faster storage (SSDs) and reducing disk reads often matter more than raw compute power.Connection handling and workload distribution
Poor connection management (too many open connections, no pooling) can slow down even a well-optimized database. Load balancing reads (replicas) and separating workloads (read vs write) is a common real-world fix.Scaling strategies (vertical + horizontal)
Vertical scaling (bigger machine) is quick but limited. Horizontal scaling (replication, sharding) is more complex but necessary at scale. Many teams on Reddit mention hitting a ceiling with vertical scaling before moving to distributed setups.
Common mistake (real-world):
A very common pattern: “Our app was slow, so we upgraded to a bigger DB instance… then it got slow again.”
This happens because the root issue (bad queries or schema) was never fixed—hardware just masked it temporarily while costs increased.
Layer interaction (this is key):
Infrastructure amplifies efficiency, it doesn’t create it
If lower layers are optimized, infra scaling gives massive gains
If not, you’re just paying more for the same inefficiency
Real-world insight:
Many experienced engineers say the same thing:
“The biggest performance wins didn’t come from scaling servers, they came from fixing queries and reducing load first.”
That’s why infrastructure should be your last optimization step, not the first.
Concurrency & Connection Layer (Controlling Load and Stability)
Why it matters:
Database performance doesn’t degrade gradually under load, it fails suddenly. As traffic increases, queries overlap, compete for locks, and exhaust connections.
In production systems, this often appears as sudden latency spikes or request queueing, even when CPU isn’t fully utilized. This isn’t usually a query problem, it’s a concurrency problem.
What to focus on:
Managing concurrent queries: Limit how many queries run at once. Too many parallel operations increase contention and unstable latency. Control throughput instead of maximizing execution.
Connection pooling and reuse: Avoid opening connections per request. Pooling reduces overhead, prevents connection exhaustion, and stabilizes performance during traffic spikes.
Reducing lock contention: Queries can block each other when accessing the same data. Keep transactions short and avoid write hotspots to reduce waiting time.
Common mistake (real-world):
Teams scale infrastructure without controlling concurrency, leading to higher costs but recurring instability.
Real-world insight:
Across many production systems, the biggest performance issues aren’t caused by slow queries, they’re caused by too many queries running at the same time.
Common patterns:
Connection limits reached during peak traffic
Queries blocked by locks despite being optimized
Latency spikes even when infrastructure isn’t saturated
In several cases, introducing:
connection pooling
concurrency limits
better transaction design
…stabilized performance without changing queries or scaling infrastructure.
To better understand where optimization fits in modern systems, explore the data warehouse vs data lake vs database comparison.
7 Techniques for Effective Database Optimization (Step-by-Step)
Database optimization works best when you follow a clear order instead of jumping between fixes. Each step builds on the previous one, helping you solve root problems instead of applying temporary patches.
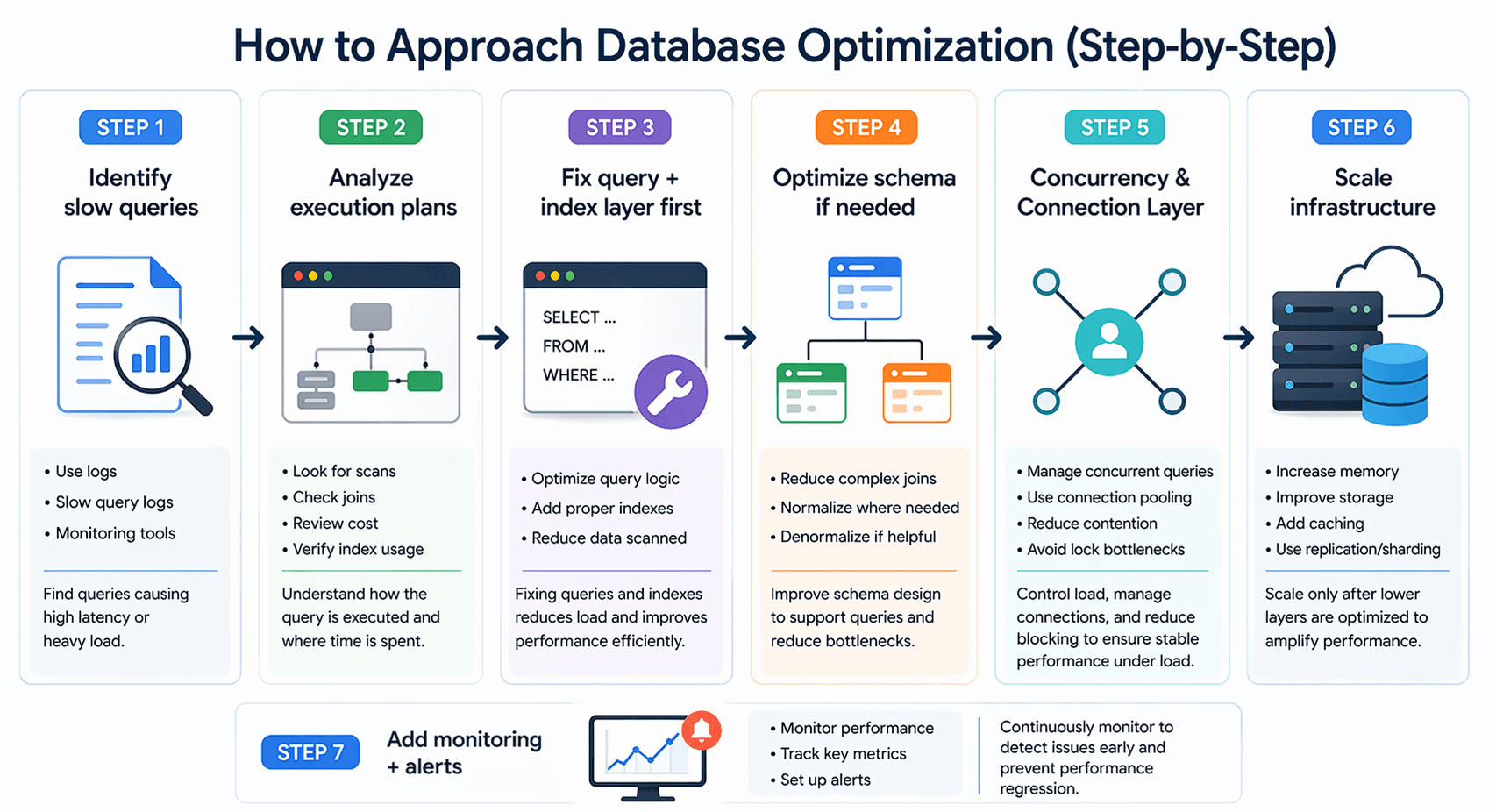
Step 1: Identify Slow Queries
Start by finding the queries that actually cause performance issues. Use logs, slow query logs, or monitoring tools to identify high-latency or frequently executed queries impacting users.
Step 2: Analyze Execution Plans
Once identified, understand how those queries run. Execution plans reveal whether the database is scanning too much data, using inefficient joins, or ignoring indexes.
Step 3: Fix Query + Index Layer First
Before scaling anything, improve query logic and ensure indexes match real access patterns. This step removes unnecessary work and delivers the biggest performance gains early.
Step 4: Optimize Schema if Needed
If performance issues persist, review your schema. Complex relationships and excessive joins often indicate a need to restructure or selectively denormalize for faster access.
Step 5: Scale Infrastructure
Only after optimizing the lower layers should you scale infrastructure. Improve memory, storage, caching, or introduce replication to handle growth efficiently without increasing inefficiency.
Step 6: Add Monitoring + Alerts
Finally, set up continuous monitoring to track performance and detect issues early. Alerts help you respond quickly and keep your database optimized as workloads evolve.
As systems scale, these challenges become even more relevant in the future of data engineering.
Database Optimization Techniques
Most articles list techniques, but the real value comes from knowing when to apply each one and what problem it actually solves. Think of these as practical levers,you use different ones depending on whether your issue is slow queries, large datasets, or system overload.
Query Optimization Techniques (Reduce Work at the Source)
This is the first place to look because inefficient queries create unnecessary load across the entire system.
Filter early (reduce data scanned)
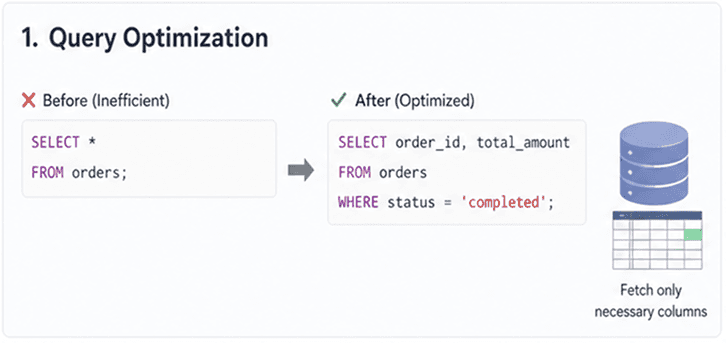
ApplyWHEREconditions as early as possible so the database processes fewer rows. The less data scanned, the faster the query execution.Avoid
SELECT *(control data retrieval)
Fetch only required columns. Retrieving extra data increases memory usage, disk I/O, and network transfer, especially in large tables.Use efficient joins (minimize data expansion)
Ensure joins are necessary, properly indexed, and operate on smaller datasets. Poor joins can multiply rows internally and significantly slow down queries.
When to use: When queries are slow, CPU usage is high, or performance degrades as data grows.
Index Optimization Techniques (Improve Data Access)
Indexes determine how quickly the database can locate required data without scanning entire tables.
Composite indexes (align with query patterns)
Create multi-column indexes that match how queries filter and sort data. The order of columns in the index should reflect actual usage.Remove unused indexes (reduce overhead)
Each index consumes storage and slows down write operations. Regularly remove indexes that are not used by queries.
When to use: When queries scan large portions of data or fail to use existing indexes effectively.
Caching Strategies (Avoid Repeated Computation)
Caching reduces database load by storing frequently accessed or expensive-to-compute results.
In-memory caching (Redis / Memcached)
Store frequently requested data in memory to reduce repeated database access and improve response time.Query/result caching (reuse outputs)
Cache results of expensive queries when the underlying data doesn’t change frequently, reducing computation and load.
When to use: When the same queries or data are requested repeatedly in read-heavy systems.
Data Partitioning (Manage Large Datasets Efficiently)
As data grows, even optimized queries can slow down due to the sheer volume being processed.
Horizontal partitioning (sharding)
Distribute data across multiple databases or nodes to balance load and improve scalability beyond a single system.Range partitioning (limit data scanned)
Divide data into logical segments (e.g., by date) so queries only scan relevant partitions instead of entire tables.
When to use: When tables become large and query performance degrades with increasing data volume.
Connection Optimization (Control System Load)
Performance issues are sometimes caused by too many concurrent requests rather than inefficient queries.
Connection pooling (reuse connections efficiently)
Maintain a pool of reusable connections to avoid the overhead of creating and closing connections repeatedly.Limit concurrent queries (prevent overload)
Control the number of simultaneous queries to avoid exhausting database resources and causing system slowdowns.
When to use: When performance drops under high traffic or during spikes in concurrent usage.
Optimized databases are critical for powering insights in modern business intelligence tools.
Common Database Optimization Mistakes
We see this a lot across teams, performance issues aren’t coming from one big problem, but from small decisions that stack up over time.
Over-indexing
Teams add indexes for every slow query. It works for a while, then write performance drops and storage grows. At one point, we had a table with 12+ indexes, reads were fine, but inserts slowed down by ~40%. Indexes should be tied to real query patterns, not assumptions.
Ignoring execution plans
This is the biggest gap. Queries get rewritten without checking how the database is actually executing them. In one case, a query looked simple but was doing a full table scan on millions of rows. A small index change reduced execution time from seconds to milliseconds. Without execution plans, optimization is guesswork.
Scaling too early
Instead of fixing queries, teams upgrade instances or move to distributed setups. We’ve seen systems scale infrastructure 2–3x when the real issue was inefficient joins. Scaling hides the problem, it doesn’t solve it.
No monitoring
Many teams don’t track slow queries until users complain. No visibility into query time, locks, or spikes. One production issue we worked on was caused by a single unoptimized query running repeatedly, no alerts, no logs. Monitoring should be in place before problems show up.
Performance optimization becomes even more important when working with AI-powered business intelligence systems.
Frequently Asked Questions (FAQs)
What does database optimization actually improve in real use?
Database optimization improves query speed, reduces load time, and keeps systems stable under traffic. For users, it means faster apps and fewer errors. For teams, it reduces costs, avoids scaling issues, and keeps performance predictable as data grows.
How can I identify slow queries in my database?
Start with slow query logs and monitoring tools. Look for queries with high execution time or frequent runs. Then check execution plans to find bottlenecks like full scans, missing indexes, or inefficient joins impacting performance.
When should I add indexes to a database?
Add indexes when queries frequently filter, sort, or join on specific columns. Don’t add them blindly. First analyze query patterns, then create indexes where they actually reduce execution time without hurting write performance or increasing storage overhead.
Why is my database slow even after adding indexes?
Indexes alone don’t fix everything. Poor query design, large data scans, too many joins, or outdated statistics can still slow things down. Sometimes, removing unnecessary indexes or rewriting queries has a bigger impact than adding new ones.
What is the fastest way to improve database performance?
The fastest wins usually come from fixing inefficient queries and adding the right indexes. Start with high-impact queries, analyze execution plans, and optimize step by step instead of making large, untested changes across the system.
Frequently Asked Questions
1. What is database optimization and why is it important?
Database optimization focuses on improving how efficiently a database processes and retrieves data. It plays a critical role in reducing delays, improving application responsiveness, and managing system resources effectively, especially as data volume and user traffic increase over time.
2. What are the most common database optimization techniques?
Widely used methods include creating indexes, refining queries, implementing caching, partitioning large tables, and optimizing schema design. These approaches help reduce processing overhead, improve query speed, and ensure smoother performance under varying workloads.
3. What is the difference between query optimization and database tuning?
Query optimization targets improving specific SQL statements for faster execution, while database tuning involves broader enhancements like indexing strategies, schema structure, and system configuration to improve overall database performance.
4. What tools are used for database optimization?
Various tools assist in monitoring and improving database performance, such as SolarWinds Database Performance Analyzer, Datadog, New Relic, MySQL Workbench, and pgAdmin. These platforms help identify slow queries, analyze workloads, and provide actionable insights for optimization.
5. What are common mistakes to avoid in database optimization?
Common pitfalls include overusing SELECT *, neglecting indexing, ignoring execution plans, running large unfiltered queries, and failing to monitor performance regularly. These issues can lead to slower response times and inefficient resource utilization.
Conclusion
Database optimization is where most teams get it wrong, not because it’s complex, but because they approach it in the wrong order.
We’ve seen this pattern repeatedly: a system slows down, the first reaction is to scale infrastructure, add indexes, or tweak configs. It works briefly. Then the same issues come back, only now they’re more expensive and harder to fix.
The real problem usually sits lower: inefficient queries, unclear access patterns, and a schema that wasn’t designed for how the data is actually used.
If there’s one shift that makes the biggest difference, it’s this:
Stop treating database optimization as a set of fixes. Start treating it as a system.
Look at how queries behave under load. Understand how data is accessed. Fix what reduces actual work,not what just masks it.
Once the lower layers are clean, everything above them, indexes, caching, infrastructure, starts working the way it should.



