
Data Engineering Solutions in 2026: Why the Smallest Reliable Architecture Wins
Looking for the right data engineering solutions in 2026? This guide reveals why the smallest reliable architecture beats complex stacks. Learn the exact 4-stage maturity path, tools, and decisions that deliver trustworthy data for business and AI.




Introduction
Organizations worldwide now pour billions into data engineering solutions to turn massive data volumes into real business value. In 2026, experts project global data creation will hit 221 zettabytes while the data engineering market reaches $105.4 billion.
Yet most teams still fight broken pipelines, questionable data quality, and surprise cloud bills.
The companies winning today refuse to chase every new tool. They deliberately build the smallest reliable architecture that consistently produces trustworthy data for both daily decisions and AI systems.
This guide gives you a clear 4-stage maturity framework so you can evaluate your current setup and make smarter moves with your data engineering solutions.
The 4 Maturity Stages of Data Engineering Solutions
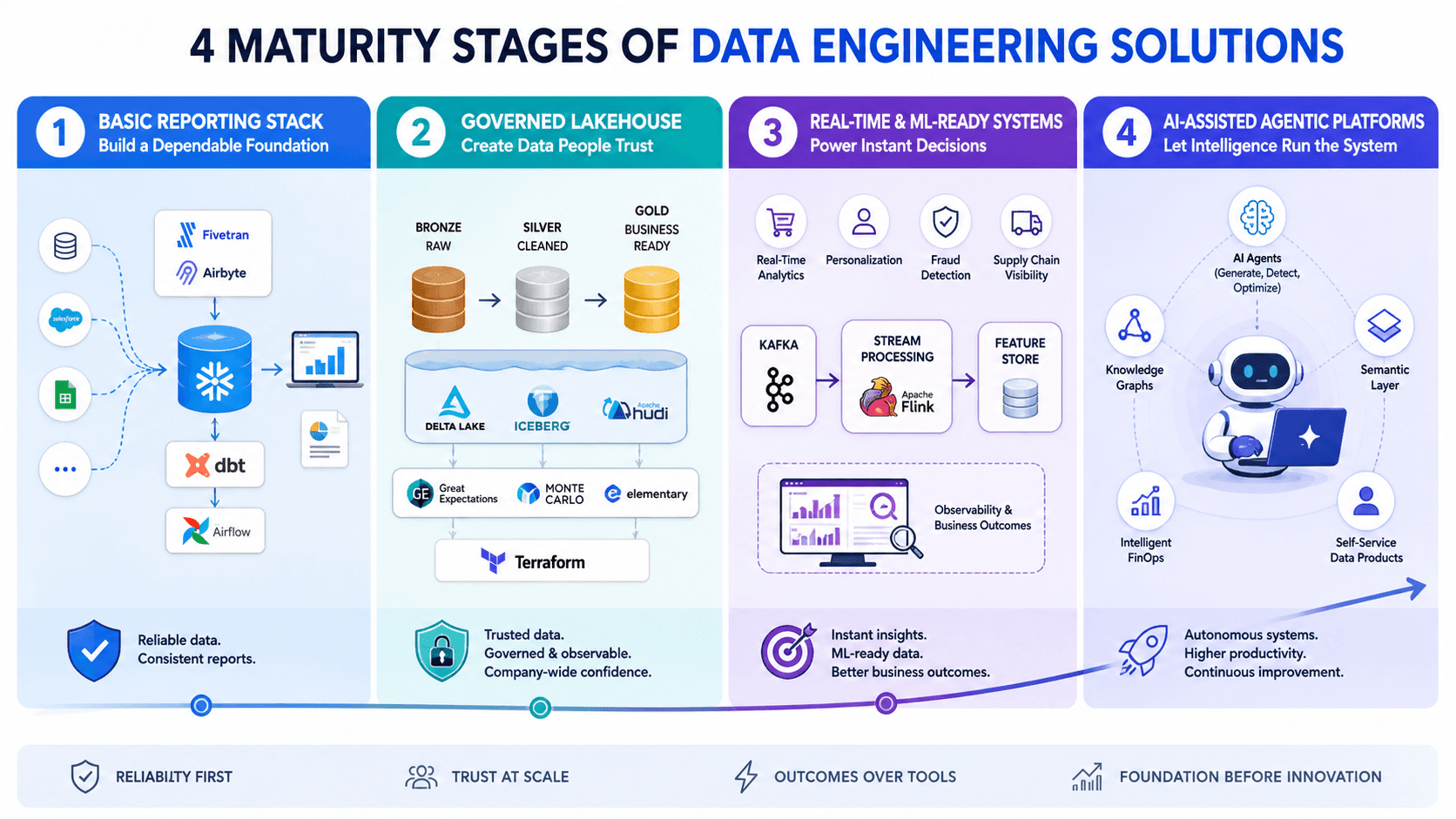
Stage 1: Basic Reporting Stack — Build a Dependable Foundation
Every successful data journey starts here. Teams focus on moving from scattered, unreliable sources to clean, consistent data that powers accurate dashboards and regular reports. Engineers often spend too many hours fixing failing pipelines instead of creating value.
At this stage, data engineering solutions stay simple and practical. You rely mainly on batch processing, a central cloud warehouse, and light automation. The main objective is reliability, not sophistication.
Smart teams choose easy-to-use tools: Fivetran or Airbyte for ingestion, Snowflake, BigQuery, or Redshift for storage, dbt for transformations, and Airflow (or managed versions) for orchestration.
Here’s a real-world example of a reliable Silver layer transformation:

Stay in Stage 1 until you achieve consistent daily reports with over 95% uptime and basic quality checks. This stage works especially well for small and mid-sized teams that want fast results without over-engineering.
Stage 2: Governed Lakehouse — Create Data People Actually Trust
This stage delivers the biggest leap in value for most organizations. You move beyond simply having data to confidently trusting it across the company.
Modern data engineering solutions in this phase use lakehouse architectures powered by Delta Lake, Apache Iceberg, or Hudi. Teams implement Medallion Architecture (Bronze raw → Silver cleaned → Gold business-ready) and add serious governance, observability, data contracts, and lineage tracking.
Tools like Great Expectations, Monte Carlo, and Elementary become essential. You also introduce Infrastructure as Code with Terraform.
Mastering this stage dramatically reduces errors in analytics and AI projects. Most companies get stuck here because they underestimate the effort required to build genuine trust at scale.
Stage 3: Real-Time & ML-Ready Systems — Power Instant Decisions
Once you have strong governance, you can confidently add real-time capabilities. This stage supports operational analytics, personalized experiences, fraud detection, supply chain visibility, and machine learning feature stores.
You introduce streaming tools such as Kafka and Flink, zero-ETL patterns, and advanced observability tied directly to business outcomes.
However, smart leaders only enter this stage when clear use cases justify the added complexity and cost. Jumping into real-time too early often creates more problems than it solves.
Stage 4: AI-Assisted Agentic Platforms — Let Intelligence Run the System
In 2026, the most advanced data engineering solutions become partially autonomous. AI agents help generate pipelines, detect issues, optimize performance, and even suggest improvements.
You add semantic layers, knowledge graphs, intelligent FinOps, and true self-service data products. Early adopters already report major productivity gains, but success depends on solid foundations from the first three stages.
How to Choose the Right Data Engineering Solutions for Your Stage
Stage | Main Goal | Best Approach | What to Avoid |
|---|---|---|---|
1 | Reliability & Speed | Managed services + dbt | Complex open-source sprawl |
2 | Governance & Trust | Lakehouse platforms (Databricks, Snowflake, Fabric) | Weak observability |
3 | Real-time & ML | Streaming + Feature Stores | Real-time for non-critical needs |
4 | Automation & Intelligence | AI-powered unified platforms | Tool sprawl and hype chasing |
Core Rule: Always add the smallest tool that solves your most pressing problem. In 2026, unnecessary complexity remains the biggest threat to reliable data systems.
Implementation Roadmap That Actually Works
Successful teams follow a disciplined path with their data engineering solutions. First, honestly assess your current maturity. Then define clear business outcomes before picking any new technology. Implement Medallion Architecture early because it scales beautifully. Treat data as a real product, assign owners, set SLAs, and maintain excellent documentation.
Adopt DataOps practices: use CI/CD pipelines, automated testing, and Git for everything. Most importantly, measure what drives real value, pipeline reliability, data freshness, cost per query, and direct business impact.
FAQ About Data Engineering Solutions
Q1: What exactly are data engineering solutions?
Data engineering solutions include the platforms, tools, architectures, and services that help organizations collect, clean, store, process, and serve high-quality data reliably for analytics and AI.
Q2: What makes the best data engineering solutions in 2026?
The best solutions deliver maximum trust with minimum complexity. They focus on reliability and business outcomes rather than featuring the longest tool list.
Q3: Should companies build data engineering solutions in-house or use managed platforms?
Use managed platforms like Databricks, Snowflake, or Microsoft Fabric for heavy lifting. Build custom logic only in areas that create genuine competitive advantage.
Q4: When should organizations adopt real-time data engineering solutions?
Adopt real-time capabilities only when specific business results — such as higher revenue, lower risk, or better customer experience — clearly require fresh data within seconds or minutes.
Q5: How much do quality data engineering solutions typically cost?
Costs range from a few thousand dollars monthly for basic setups to hundreds of thousands for advanced enterprise systems. Always evaluate total cost of ownership and expected return on investment.
Q6: Why have lakehouses become central to modern data engineering solutions?
Lakehouses combine the low cost and flexibility of data lakes with the reliability, governance, and performance of traditional warehouses, making them ideal for today’s mixed analytics and AI workloads.
Q7: How is AI changing data engineering solutions?
AI now automates routine pipeline work while raising the bar for data quality. Reliable data engineering solutions have become even more critical because poor data makes AI systems fail expensively.
Q8: What is the most common mistake with data engineering solutions?
Building overly complex architectures and chasing every new tool instead of focusing on simple, reliable systems that solve actual business problems.
Final Thoughts
In 2026, the winners choose data engineering solutions that prioritize reliability over complexity. They build the smallest architecture that consistently delivers trustworthy data and they stay disciplined as they grow.
Take a moment right now to identify which stage your organization currently occupies. Then pick one focused improvement that will move you forward.



