
DBT Explained: What It Is, How It Works, and Why Teams Use It
Understand DBT, what it means, how it works, and why modern data teams use it to build reliable, tested, and scalable analytics pipelines.



Introduction
At some point, almost every data team hits the same wall.
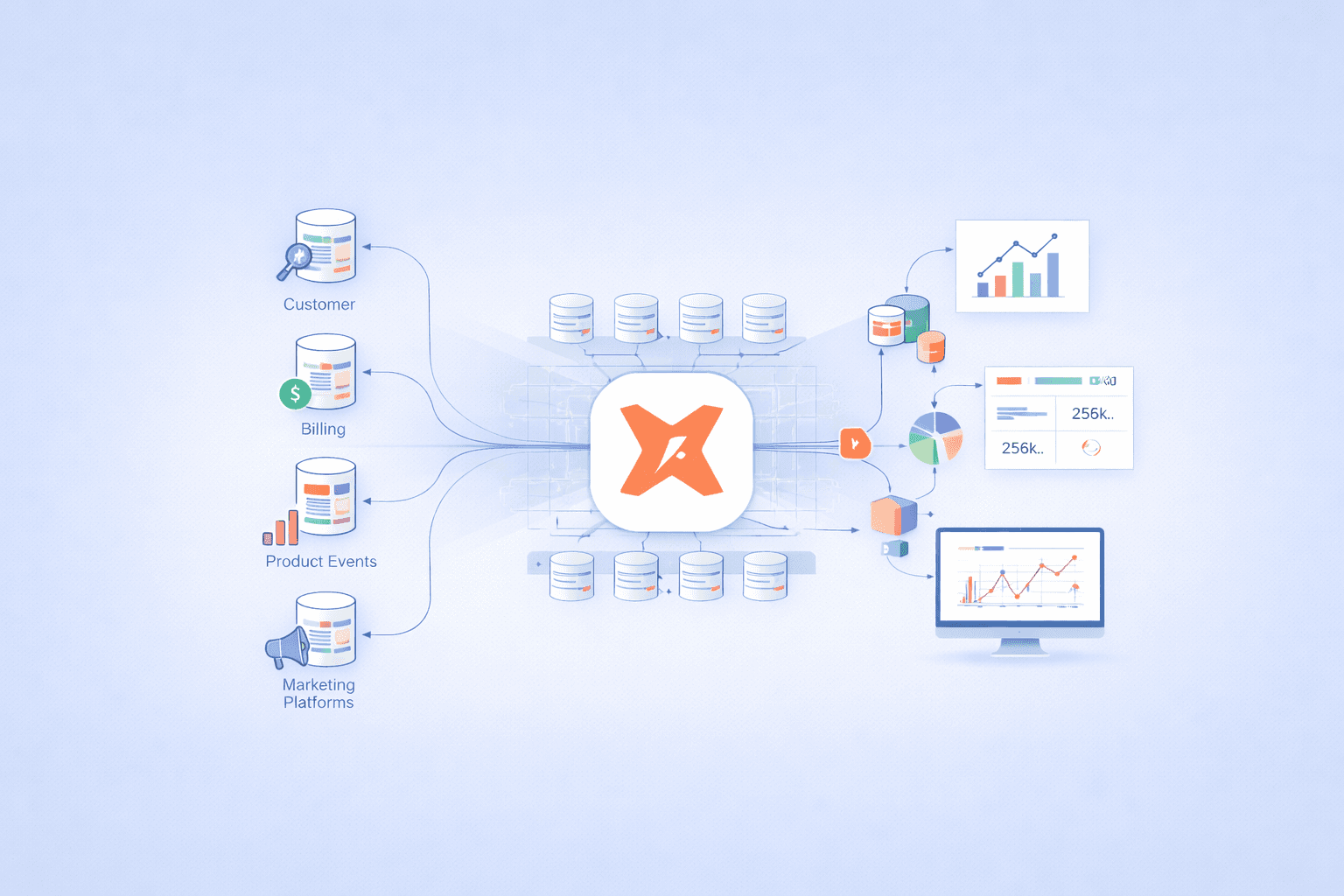
Data is coming in from everywhere. Product events, billing systems, CRM tools, marketing platforms. The warehouse keeps growing, but clarity does not. Analysts write SQL directly on raw tables. Logic gets copied, pasted, slightly changed, and pasted again. Nobody is fully sure which table powers which dashboard anymore.
And on top of that, there’s pressure.
Not enough engineers. Not enough time. Stakeholders want answers yesterday.
This is usually the moment teams start looking for structure, not another dashboard tool, not another ingestion connector, but a way to bring discipline to how data is transformed.
That’s where DBT enters the picture.
What Is DBT?
DBT, short for data build tool, is a framework that helps teams transform data inside the warehouse using SQL, but with engineering discipline layered on top.
It does not move data. It does not visualize data. It does not magically fix upstream problems.
What it does is surprisingly focused:
DBT turns messy transformation logic into version-controlled, testable, documented models that live alongside code.
If you already have data in Snowflake, BigQuery, or Redshift, DBT lets you define how that data should be shaped, step by step, in a way that scales as teams and complexity grow.
Think of it as the moment analytics stopped being “a bunch of queries” and started behaving more like software.
How Is DBT Different Than Other Tools?
This is where a lot of confusion starts, especially for teams early in their data journey.
DBT is not an ETL tool.
It’s not a BI tool.
It’s not a scheduling system, though it works with one.
Traditional ETL tools extract data, transform it somewhere else, then load it. DBT flips that idea. Data is already in the warehouse. DBT transforms it inside the warehouse, using SQL that your analysts already know.
And unlike point-and-click tools, DBT assumes:
You use Git
You care about reviews
You want CI/CD for data
You expect tests to fail when assumptions break
That mindset shift matters.
DBT treats analytics like production code, even when the team writing it is small, busy, and stretched thin.
What Can DBT Do for My Data Pipeline?
This is where DBT quietly earns its reputation.
It creates a single place for business logic
Instead of logic being scattered across dashboards and ad-hoc queries, DBT centralizes transformations. Metrics stop drifting. Definitions become consistent.
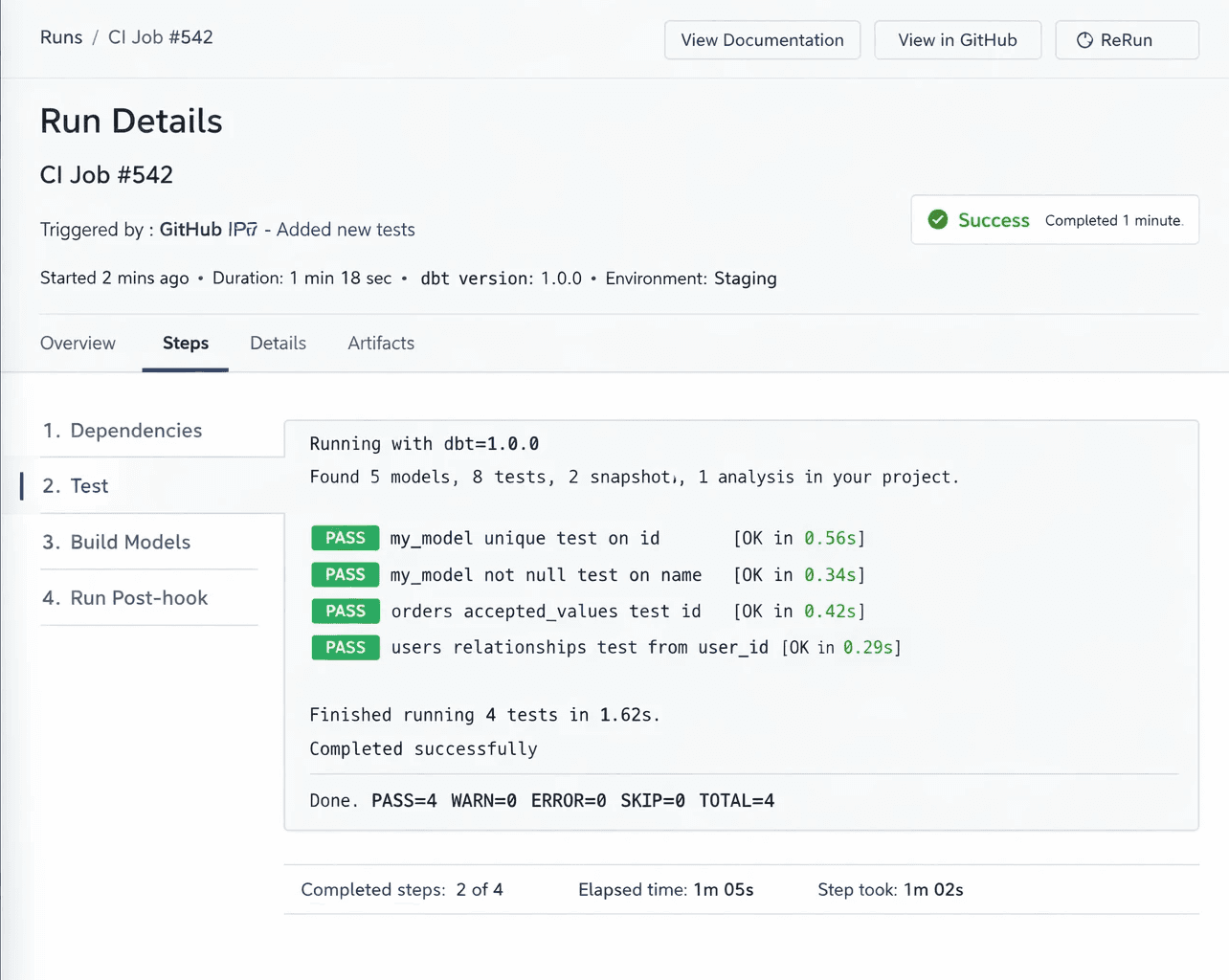
It adds guardrails through testing
YAML-based tests check things like:
Primary keys not being null
Relationships holding up
Row counts not unexpectedly dropping
These tests don’t eliminate errors, but they surface problems early — often before a stakeholder notices something is off.
It gives you lineage you can actually trust
When a model breaks, DBT shows what depends on it. That visibility changes how confidently teams ship changes.
It fits into real engineering workflows
DBT works naturally with GitHub, pull requests, CI pipelines, and scheduled runs. Changes are reviewed. Models are tested. Deployments are predictable.
This is especially important when data teams are understaffed. You don’t have time to manually sanity-check everything.
DBT Documentation: Helpful, But Not the Whole Story
One of DBT’s underrated features is how it generates documentation automatically.
From model and column descriptions to dependency graphs, DBT docs give teams a living map of their analytics layer. You don’t document after the fact. Documentation lives with the code.
Running
spins up a site where you can explore models, see lineage, and understand dependencies. For engineers and analytics folks, it’s invaluable. It answers questions like:
“Where does this metric come from?”
“If I change this model, what breaks?”
That said, DBT documentation is still technical by nature. It explains how data is built, not always why it exists or how the business uses it. That gap becomes more noticeable as more non-technical stakeholders rely on data outputs.
Real-World DBT Usage: What It Looks Like in Practice
In practice, DBT projects evolve in stages.
Early on, teams write simple models. Then complexity grows. Jinja macros appear to reduce repetition. Snapshots are added to track changes over time. Models are split into staging, intermediate, and marts.
Eventually, DBT becomes the backbone of the analytics layer.
At that stage, teams start integrating:
GitHub for version control
CI pipelines that run DBT tests on pull requests
Scheduled runs aligned with business cadence
Naming conventions enforced across projects
This is where DBT stops being “a tool” and becomes infrastructure.
What DBT Does Not Solve (And Why That’s Okay)
DBT does not solve everything. And that’s intentional.
It does not:
Replace BI tools
Make analytics no-code
Explain metrics in business language
Manage ingestion pipelines
DBT is built for technical users. Analysts, analytics engineers, data engineers. That focus is its strength.
Most teams eventually pair DBT with tools that sit above it — tools that help business users explore data, understand metrics, and ask questions without writing SQL. DBT ensures the foundation is solid. Other tools focus on accessibility.
Trying to make DBT do everything usually leads to frustration.
How Can I Get Started with DBT?
Most teams start small.
A single warehouse. A handful of models. One or two people owning the project. That’s enough.
The key is not perfection. It’s consistency. Write models clearly. Add tests where failures would hurt. Document things that would confuse the next person — because that next person might be you, six months later, under deadline pressure.
DBT rewards teams that think long-term, even when moving fast.
Training to Learn How to Use DBT
DBT is approachable, but it’s not trivial.
Teams usually learn it by:
Reading official docs alongside real projects
Reviewing existing DBT repos
Learning SQL modeling patterns
Understanding Git workflows
Getting comfortable with YAML, tests, and macros
The learning curve isn’t steep, but it’s real. Especially for teams transitioning from ad-hoc analytics to structured pipelines.
The payoff, though, is significant. Fewer surprises. More confidence. Less firefighting.
When DBT Feels Like Too Much: Why Some Teams Turn to AI BI Tools
There’s also a reality many teams quietly face.
Not every organization has the time, talent, or appetite to build and maintain a deeply technical analytics stack. DBT requires SQL skills, version control, testing discipline, and ongoing ownership. For some teams, that investment makes sense. For others, it becomes a bottleneck.
This is one reason AI-powered BI tools have seen rapid adoption across enterprises.
Instead of requiring deep modeling expertise, AI BI tools focus on:
Asking questions in natural language
Automatically generating insights
Reducing dependency on analytics engineers
Speeding up decision-making for non-technical teams
In environments where engineering resources are limited or business teams need answers quickly, these tools can unlock value without heavy technical setup.
Many organizations now use a hybrid approach:
DBT ensures data is structured and reliable
AI BI tools sit on top, making insights accessible to a broader audience
This shift isn’t about choosing “technical vs non-technical” tools. It’s about matching the tool to the team, the timeline, and the business reality.
As analytics continues to evolve, flexibility matters just as much as correctness.
Final Thoughts
DBT doesn’t promise magic. It promises structure.
For teams dealing with data sprawl, limited engineering bandwidth, and constant time pressure, that structure can be transformative. It turns analytics from a fragile set of queries into something teams can trust, maintain, and scale.
DBT works best when it’s treated not as a quick fix, but as a foundation. Build carefully. Review often. Document honestly. And accept that data work, like software, is never really “done”.
That mindset shift is where DBT’s real value shows up.



