
Is AI BI Just Text-to-SQL? The Honest Difference (With Examples)
Text-to-SQL turns a question into a query. AI-native BI understands the business. Here's the real difference, with a worked NRR example and a 5-min test.

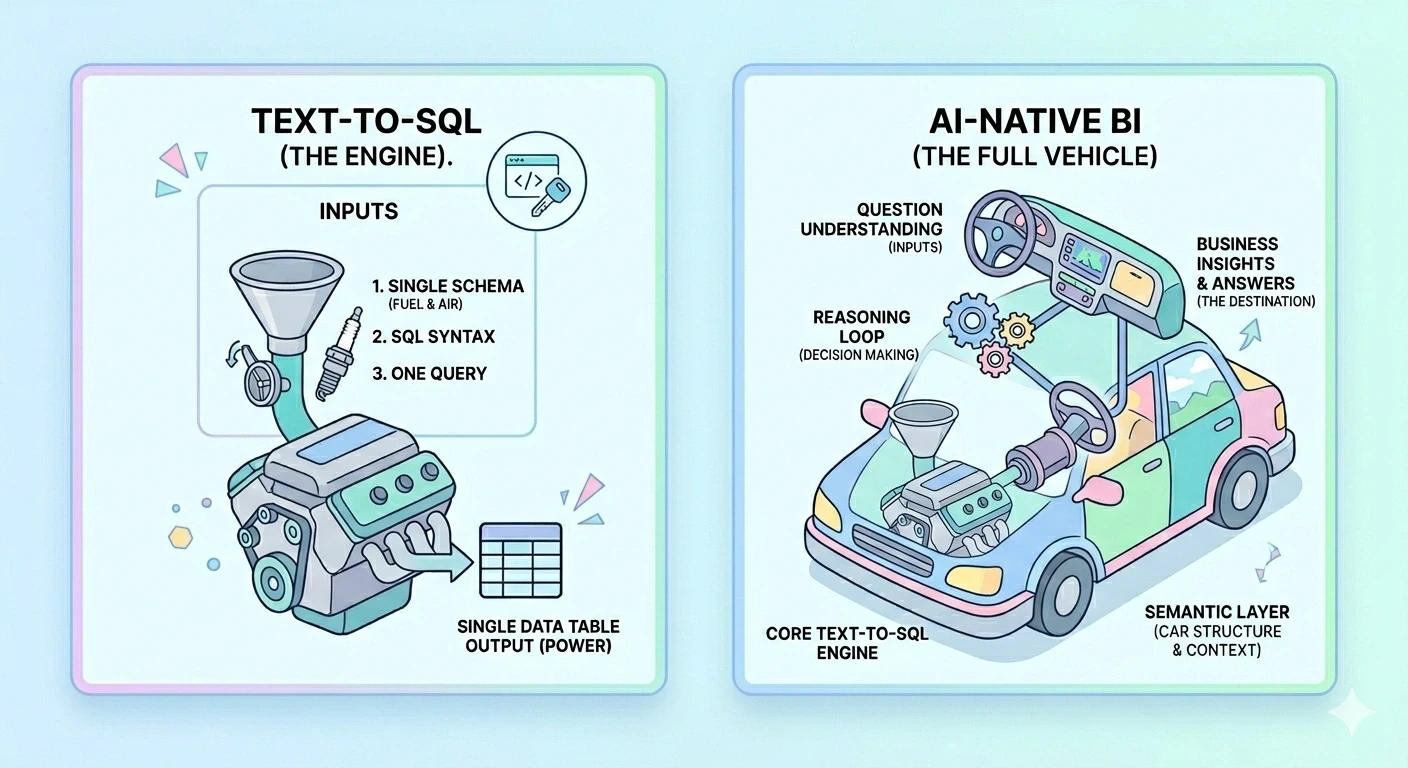

Is AI BI Just Text-to-SQL? Let's Be Honest About It
I hear this objection more than any other. Sometimes it's a buyer halfway through a demo. Sometimes it's a competitor on a comparison page. The shape is always the same: "This whole category is just text-to-SQL with a chat box on top. You ask a question, it writes some SQL, it runs it. Cute UI. Nothing new."
I want to take that objection seriously, because the lazy version of my answer ("no, we're different, trust me") is exactly what makes people believe it. So I'm going to state the objection in its strongest form, agree with the parts that are true, and then show you precisely where it stops being true. By the end you'll have a test you can run in five minutes on any tool, including mine.
The objection, stated fairly
Here is the strong version, not a strawman.
Large language models are genuinely good at translating natural language into SQL. Feed a model a schema and a question, and it will produce a query that is correct a remarkable share of the time. This is a real, hard problem that used to require a human analyst, and it is now substantially solved for a wide class of questions. So the skeptic says: every "AI BI" product is some flavor of this.
The differences between them are cosmetic. Better autocomplete, nicer charts, a friendlier onboarding. Under the hood it is the same trick: question in, SQL out, table back. Calling that "AI-native business intelligence" is marketing inflation. It is text-to-SQL wearing a blazer.
I think that objection is correct about the mechanism and wrong about the category. Both of those can be true at once, and the rest of this post is about why.
What text-to-SQL actually is (and what it's genuinely good at)
Let me define it cleanly, because half the confusion is definitional.
Text-to-SQL is the task of translating a natural-language question into a SQL query that runs against a known database schema. The input is a question and a schema. The output is a query. Its job ends the moment a valid query is produced.
That is a precise scope, and within it text-to-SQL is excellent. It is very good at single-source questions where the schema is clean and the definitions are unambiguous. "How many orders did we get yesterday." "Top ten products by revenue this month." "Average order value by region." If your question maps cleanly onto one well-named table, or a couple of obviously related ones, modern text-to-SQL will answer it faster and more reliably than most humans, and it will do it at 2am without complaint.
I am not damning it with faint praise. Text-to-SQL collapsed a real bottleneck. The analyst queue, where every "quick question" took three days because someone had to write the query, is largely gone for this class of question. That is a genuine advance and I would not want to build without it.
The trouble is that the questions that actually matter to a business are almost never this class of question.
What AI-native BI actually is
AI-native BI is a system that answers business questions by understanding the business, not just the schema. It joins data across multiple sources, applies the organisation's own definitions of its metrics through a semantic layer, and reasons about cause rather than only retrieving rows.
Text-to-SQL is a component inside it. It is not the whole thing. The distinction in one sentence, since you'll want the quotable version:
Text-to-SQL translates a question into a query against one schema. AI-native BI understands the business well enough to know which query is even the right one to ask.
Everything below is an unpacking of that sentence.
Where text-to-SQL breaks: a worked example
Let me make this concrete, because abstractions are where these debates go to die. One real question carries this whole argument.
The question is: "Why did our net revenue retention drop last quarter?”
This is not an exotic question. It is the single most common question a SaaS CFO or founder asks. And it breaks pure text-to-SQL on three separate axes at once. Watch.
Axis one: the data lives in three places
Net revenue retention is not stored anywhere. It has to be assembled. In a typical setup the pieces look like this:
Stripe holds the money: subscriptions, invoices, refunds, plan changes, currency.
The Postgres application database holds the product reality:
accounts,subscriptions,users,seats, and crucially thestatusfield that says whether an account is active, paused, in trial, or delinquent.HubSpot holds the human context: which accounts have an assigned CSM, renewal dates, support escalations, the segment an account was sold into.
There is no single schema here. There is no table you can point a text-to-SQL model at and say "compute NRR." To even begin, the system has to know that a Stripe customer maps to a Postgres account maps to a HubSpot company, and that the join keys are inconsistent (Stripe uses an email or a metadata field, Postgres uses a UUID, HubSpot uses its own ID). A schema-bound model does not know these three systems are describing the same customers. It cannot join across databases it was never shown, using keys nobody told it were equivalent.
Axis two: the definition is a business decision, not a column
Now suppose you've solved the join. You still have to define net revenue retention, and that definition is where the real answer hides.
NRR measures how revenue from your existing customers changed over a period: expansion and upsell minus contraction and churn. The denominator is the revenue from a cohort of customers you had at the start of the period. The numerator is what that same cohort is worth at the end.
The phrase that decides everything is "customers you had." Specifically: which customers count?
In this business, an active customer excludes paused and trial accounts. Paused accounts are still in Stripe with a live subscription object, but they are not paying and the product knows it via the Postgres status field. Trial accounts have a subscription too, but they were never in the retention base to begin with. If you count paused and trial accounts as part of your starting cohort, your NRR math is wrong in a way that looks completely plausible. The number will be a number. It will be the wrong number.
A text-to-SQL model handed "net revenue retention" will do something reasonable-looking. It will probably sum subscription revenue at two points in time and divide. It will almost certainly count every subscription in Stripe as a customer, because nothing in the Stripe schema tells it that a paused account in Postgres should be excluded. It has no way to know your definition, because your definition is not in any schema. It is in your head, in a Notion doc, in the way your finance team has always done it. The model cannot read your mind, and "active customer" is a mind-read.
This is the core of it. The hard part of the question is not the SQL. It's knowing which SQL is correct, and correctness here is defined by the business, not the database.
Axis three: the question is "why," not "what"
Even if the join is right and the definition is right, you have only computed that NRR dropped, from 112% to 104% say. The CFO did not ask what NRR is. They asked why it fell.
"Why" is not a retrieval operation. There is no WHERE reason = 'the cause' clause. Answering it means decomposing the drop into its parts (did expansion slow, or did contraction rise?), then attributing the movement (was it concentrated in one segment, one plan tier, one cohort, accounts without an assigned CSM?), then checking the candidate explanations against the data and discarding the ones that don't hold. That is a reasoning loop: form a hypothesis, query to test it, read the result, form the next hypothesis. It can take eight or twelve queries, each one depending on what the last one returned.
Text-to-SQL produces one query per question. It does not carry a hypothesis across queries. It does not decide what to ask next based on what it just learned. The "why" question is not bigger than text-to-SQL. It is a different kind of task that text-to-SQL is not built to do.
So this one ordinary question breaks pure text-to-SQL three ways: it needs a join across sources the model was never shown, a definition the schema does not contain, and a chain of reasoning rather than a single lookup. None of those gaps is closed by a better SQL-writing model. They are closed by what you build around it.
What "understanding the business" actually requires
"Understanding the business" sounds like a slogan, so let me define it as three concrete things you can point at.
A semantic layer. This is the place where your metrics are defined once, in business terms, independent of any single source schema. "Net revenue retention," "active customer," "expansion," "logo churn" each get a single canonical definition that says what tables and conditions they map to, including the rule that active excludes paused and trial. When a question comes in, the system resolves it against these definitions instead of guessing from column names. The semantic layer is how "active customer" stops being a mind-read and becomes a fact the system can apply consistently every time.
Business context. The semantic layer defines metrics; business context is everything around them that makes a metric meaningful. Which source is authoritative when two disagree. How a Stripe customer maps to a Postgres account maps to a HubSpot company. That fiscal quarters start in February. That the EMEA segment was reorganized in March so cohort comparisons across that date need care. This is the institutional knowledge a good analyst accumulates over years, made explicit so the system can use it.
Reasoning. This is the ability to pursue a question across multiple steps: to form a hypothesis, write a query to test it, interpret the result, and decide what to ask next, until the question is actually answered rather than merely queried. It is the difference between a tool that returns a table and an agent that returns an answer.
A system that has all three understands the business. A system that has none of them, however good its SQL, is doing translation. That is the whole distinction, and it is not cosmetic.
Text-to-SQL vs AI-native BI: the contrasts that matter
Not a giant matrix. Five distinct dimensions you can lift directly.
1. Scope of input. Text-to-SQL takes a question and one schema. AI-native BI takes a question and a model of the business: multiple sources, their relationships, and the definitions that govern them.
2. Source of correctness. In text-to-SQL, a query is "correct" if it is valid SQL that matches the schema. In AI-native BI, a query is correct only if it matches the business's definition of the metric, which the schema does not contain.
3. Joins across systems. Text-to-SQL joins tables within a database it was shown. AI-native BI joins across Stripe, Postgres, and HubSpot using mappings the raw schemas don't encode.
4. Single query vs reasoning loop. Text-to-SQL emits one query per question. AI-native BI runs a chain of queries where each step depends on the last, which is what "why" questions require.
5. What you maintain. With text-to-SQL you maintain prompts and schema hints. With AI-native BI you maintain a semantic layer and business context that the system reuses on every question, so it gets more right over time instead of re-guessing each time.
The honest middle ground
Here is the concession the skeptic is right to demand, and the one that makes everything above credible.
Every AI BI tool, including mine, uses text-to-SQL under the hood. At the bottom of the stack, when it is time to actually fetch rows, the system generates SQL and runs it against a database. There is no avoiding this and no shame in it. SQL is how you query a relational database. Anyone who tells you their AI BI product has transcended SQL is selling you something.
So the difference is not whether text-to-SQL is present. It is present in all of us. The difference is what sits around it. A semantic layer that tells the SQL generator what "active customer" means before it writes a line. A mapping layer that lets it join three systems. A reasoning loop that decides which queries to write and in what order. A training mechanism so the system learns your definitions instead of re-deriving them every session.
Text-to-SQL is an engine. Whether you have a car depends on everything else. The objection "you're just text-to-SQL with a wrapper" is, in a literal sense, like saying a car is just an engine with a wrapper. The engine is real and essential. It is also not the thing you drive.
This is the framing I'd want a buyer to leave with: don't ask whether a tool uses text-to-SQL. Assume it does. Ask what it has wrapped around it, and whether that wrapping understands your business.
How to tell the difference in five minutes
You don't need to read architecture diagrams. You need three questions and one real metric of your own. Here's the test I'd run on any tool, including Supaboard.
Minute 1 — Ask it your hardest defined metric. Pick a metric where your definition differs from the obvious one. NRR with paused accounts excluded. "Active customer" with your real exclusions. Margin with your real cost allocation. Ask the tool for it cold, with no setup. If it gives you a confident number that silently uses the naive definition, you've learned something: it's translating, not understanding.
Minute 2 — Make it cross sources. Ask something that requires two systems to meet. "Show me NRR for accounts with an assigned CSM versus those without." CSM assignment lives in your CRM; revenue lives in billing. A pure text-to-SQL tool pointed at one warehouse table will either fail or quietly drop the part it can't reach.
Minute 3 — Ask "why." Take the result and ask why. "Why is retention lower for the no-CSM group?" Watch whether it runs a single query and restates the number, or whether it decomposes, hypothesizes, and tests. One is retrieval. The other is reasoning.
Minutes 4 and 5 — Correct it, then re-ask. Tell it your real definition: "active excludes paused and trial." Then ask the original question again, and ideally a related one tomorrow. Does the correction stick and generalize, or do you have to re-explain it every session? A tool with a semantic layer learns. A wrapper forgets.
If a tool passes all three of the first questions and remembers your correction, it understands your business. If it fails them, it's a very good SQL writer with a chat box. Both are useful. They are not the same product, and now you can tell which one you're looking at in the time it takes to drink a coffee.
That's the honest answer to "is AI BI just text-to-SQL." No. It contains text-to-SQL the way a car contains an engine. The category is real because the hard part of a business question was never the SQL. It was knowing which question to ask, what your words mean, and why the number moved. Build for that and you're doing something genuinely different. Skip it and the skeptic is right about you.
FAQ
Is AI BI just text-to-SQL?
No, though it includes text-to-SQL as a component. Text-to-SQL translates a question into a query against one schema. AI-native BI adds a semantic layer for your metric definitions, mappings to join across sources like Stripe, Postgres, and your CRM, and a reasoning loop for "why" questions. The SQL generation is the engine; the understanding is everything around it.
What's the difference between text-to-SQL and AI BI?
Text-to-SQL answers "what is the number" for a single, well-defined schema. AI-native BI answers "what does this mean for the business," which requires knowing your definitions, joining across systems, and reasoning about cause. The clearest tell: text-to-SQL's idea of "correct" is valid SQL; AI BI's idea of correct is your business's actual definition of the metric.
What are the limitations of text-to-SQL?
It is bound to one schema, so it struggles to join across separate systems it wasn't shown. It can't know business definitions that live outside the schema, like "active customer excludes paused accounts," so it silently uses naive ones. And it produces one query per question, which means it can't carry a hypothesis across the multiple steps that "why" questions need.
Do AI BI tools use text-to-SQL?
Yes, essentially all of them do, including Supaboard. SQL is how you query a relational database, so generating it is unavoidable. The real question is never whether a tool uses text-to-SQL but what it wraps around it: a semantic layer, cross-source mappings, reasoning, and a way to learn your definitions over time.
How can AI be used for data analysis if it's more than text-to-SQL?
An AI agent for data analysis goes beyond writing one query: it resolves your question against canonical metric definitions, joins the relevant sources, runs a chain of queries to test explanations, and returns a reasoned answer rather than a raw table. That combination, not the SQL step alone, is what data analysis using generative AI looks like when it's done well.
